ORM API¶
モデル¶
モデルフィールドは、モデル自体の属性として定義されます。
from odoo import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
警告
つまり、同じ名前のフィールドとメソッドを定義することはできません。最後のフィールドは、黙って上書きされます。
デフォルトでは、フィールドのラベル(ユーザーに見える名前)は、大文字のフィールド名のバージョンです。これは、string パラメータで上書きできます。
field2 = fields.Integer(string="Field Label")
フィールドの型とパラメータのリストについては、 :ref:`the fields reference <reference/fields> ` を参照してください。
デフォルト値は、値としてフィールドにパラメータとして定義されます:
name = fields.Char(default="a value")
または、デフォルト値を計算するために呼び出される関数として、以下の値を返す必要があります。
def _default_name(self):
return self.get_value()
name = fields.Char(default=lambda self: self._default_name())
API
AbstractModel¶
モデル¶
TransientModel¶
フィールド¶
ベーシックフィールド¶
詳細フィールド¶
Date(time) フィールド¶
Dates and Datetimes
are very important fields in any kind of business application.
Their misuse can create invisible yet painful bugs, this section
aims to provide Odoo developers with the knowledge required
to avoid misusing these fields.
日付/日付フィールドに値を割り当てる場合、次のオプションが有効です。
dateまたはdatetimeオブジェクト。適切なサーバーフォーマットの文字列:
YYYY-MM-DDforDatefieldsYYYY-MM-DD HH:MM:SSforDatetimeフィールド。
FalseまたはNone。
Date および Datetime フィールドクラスには、互換性のある型への変換を試みるヘルパーメソッドがあります。
to_date()はdatetime.dateに変換されます。to_datetime()はdatetime.datetimeに変換されます。
Example
外部ソースからの日付/日付を解析するには:
fields.Date.to_date(self._context.get('date_from'))
日付/日付比較のベストプラクティス:
日付フィールドは、日付オブジェクトと比較できます。
Datetime項目はdatetimeオブジェクトと比較することができます。
警告
日付と日付を表す文字列は、互いに比較することができますが、結果が期待される結果ではないかもしれません。 datetime文字列は常に日付文字列よりも大きくなりますので、この方法は 重い はお勧めできません。
Common operations with dates and datetimes such as addition, subtraction or
fetching the start/end of a period are exposed through both
Date and Datetime.
These helpers are also available by importing odoo.tools.date_utils.
注釈
Timezones
datetimeフィールドは、データベースに「timezoneなしのtimestamp」列として保存され、UTCタイムゾーンに保存されます。 これは、Odooデータベースをホスティングサーバーシステムのタイムゾーンから独立させるため、設計によるものです。 タイムゾーンの変換は、クライアント側で完全に管理されます。
リレーショナルフィールド¶
疑似リレーショナルフィールド¶
計算フィールド¶
compute パラメータを使用してフィールドを計算することができます。フィールドに計算された値を割り当てる必要があります 。 他の*フィールド*の値を使用する場合は、 depends() を使用してこれらのフィールドを指定する必要があります。
from odoo import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
依存関係は、サブフィールドを使用する場合に点在するパスを指定できます:
@api.depends('line_ids.value') def _compute_total(self): for record in self: record.total = sum(line.value for line in record.line_ids)
デフォルトでは計算されたフィールドは保存されず、要求されたときに返されます。
store=Trueを設定すると、データベースに保存され、自動的に検索が有効になります。searchパラメータを設定することで、計算されたフィールドの検索を有効にすることもできます。値は ドメインを検索 を返すメソッド名です。upper_name = field.Char(compute='_compute_upper', search='_search_upper') def _search_upper(self, operator, value): if operator == 'like': operator = 'ilike' return [('name', operator, value)]
モデルで実際の検索を行う前にドメインを処理するときに検索メソッドが呼び出されます。 条件に相当するドメインを返さなければなりません:
field operator value。
計算されたフィールドはデフォルトで読み取り専用です。計算されたフィールドに setting 値を許可するには、
inverseパラメータを使用します。 これは、計算を逆にして関連するフィールドを設定する関数の名前です:document = fields.Char(compute='_get_document', inverse='_set_document') def _get_document(self): for record in self: with open(record.get_document_path) as f: record.document = f.read() def _set_document(self): for record in self: if not record.document: continue with open(record.get_document_path()) as f: f.write(record.document)
同じメソッドで複数のフィールドを同時に計算できます。 すべてのフィールドで同じメソッドを使用して、すべてのフィールドを設定するだけです。
discount_value = fields.Float(compute='_apply_discount') total = fields.Float(compute='_apply_discount') @api.depends('value', 'discount') def _apply_discount(self): for record in self: # compute actual discount from discount percentage discount = record.value * record.discount record.discount_value = discount record.total = record.value - discount
警告
複数のフィールドで同じ計算方法を使用することは可能ですが、逆方式でも同じ計算方法を使用することは推奨されません。
逆方向の計算では、**すべての**フィールドは保護されます。 値がキャッシュにないとしても計算できないということです
これらのフィールドのいずれかがアクセスされ、その値がキャッシュにない場合 ORMはこれらのフィールドのデフォルト値`False`を返します。 これは、逆フィールドの値(逆メソッドをトリガーするもの以外)が正しい値を与えない可能性があることを意味し、これはおそらく逆メソッドの期待される動作を壊すでしょう。
自動フィールド¶
- Model.id¶
識別子
field現在の recordset の長さが 1 の場合、その中に一意のレコードの id を返します。
そうでない場合はエラーを発生させます。
- Model.display_name¶
Webクライアントにデフォルトで表示される名前
fieldデフォルトでは、
_compute_display_nameをオーバーライドすることで動作をカスタマイズできます。
アクセスログ フィールド¶
これらのフィールドは、 _log_access が有効な場合に自動的に設定され、更新されます。 これらのフィールドは役に立たないテーブルの作成や更新を避けるために無効にすることができます。
デフォルトでは、 _log_access は _auto と同じ値に設定されています。
- Model.create_date¶
レコードが作成されたときに保存します。
Datetime
- Model.write_date¶
Datetimeレコードが最後に更新されたときに保存されます。
警告
_log_access must は TransientModel で有効にする必要があります。
予約されたフィールド名¶
いくつかのフィールド名は、自動化されたフィールドを超えて事前に定義された動作のために予約されています。 関連する動作が必要な場合は、モデル上で定義する必要があります。
- Model.name¶
:attr:`~odoo.models.BaseModel._rec_name`のデフォルト値は、代表的な「名前」が必要なコンテキストでレコードを表示するために使用されます。
Char
- Model.active¶
activeがFalseに設定されている場合、レコードはほとんどの検索やリストでは非表示になります。Boolean特別な方法:
- Model.state¶
オブジェクトのライフサイクルステージ。
fields <odoo.fields.Field> ` の ``states`属性で使用されます。Selection
- Model.parent_id¶
:attr:の default_value
~._parent_nameは、ツリー構造内のレコードを整理するために使用され、ドメイン内でchild_ofとparent_of演算子を有効にします。Many2one
- Model.parent_path¶
_parent_storeが True に設定されている場合、のツリー構造を反映した値を格納します。 parent_name、および検索領域の演算子``child_of`` とparent_ofを最適化するには、適切な操作を行うためにindex=Trueで宣言する必要があります。Char
- Model.company_id¶
Odoo マルチ企業の動作に使用されるメインフィールド名。
複数の会社の一貫性を確認するために`:meth:~odoo.models._check_company`が使用します。 レコードを企業間で共有するか(価値なし)、または特定の会社のユーザーだけがアクセスできるかどうかを定義します。
Many2one:type:res_company
レコードセット¶
モデルとレコードとの相互作用は、同じモデルのレコードの順序付けされたコレクションであるrecordsetを介して行われます。
警告
名前の意味とは異なり、現在は重複したレコードセットを含めることができます。これは将来的に変更される可能性があります。
モデルで定義されたメソッドはレコードセット上で実行され、self は recordset:
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self can be anything between 0 records and all records in the
# database
self.do_operation()
レコードセットに反復すると、*単一レコード*(「シングルトン」)の新しいセットが生成されます。 Python の文字列を繰り返すのと同じように、以下のような文字列があります。
def do_operation(self):
print(self) # => a.model(1, 2, 3, 4, 5)
for record in self:
print(record) # => a.model(1), then a.model(2), then a.model(3), ...
フィールドアクセス¶
Recordsets は "Active Record" インターフェイスを提供します。モデル項目はレコードから属性として直接読み書きすることができます。
注釈
潜在的に複数のレコードのレコードセット上で非リレーショナルフィールドにアクセスする場合は、 maped():
total_qty = sum(self.mapped('qty'))
フィールドの値は、動的なフィールド名の getattr() よりもエレガントで安全なdict アイテムのようにアクセスすることもできます。 フィールドの値を設定すると、データベースへの更新がトリガーされます:
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
>>> field = "name"
>>> record[field]
Bob
警告
複数のレコードのフィールドを読み込もうとすると、非リレーショナルフィールドのエラーが発生します。
リレーショナルフィールドへのアクセス (Many2one, One2many, Many2many) 常時 はレコードセットを返します。フィールドが設定されていない場合は空です。
キャッシュとプリフェッチを記録¶
Odooは、レコードのフィールドのためのキャッシュを維持します。 すべてのフィールドアクセスがデータベースの要求を発行するわけではありませんが、パフォーマンスに悪影響を及ぼす可能性があります。 以下の例では、最初の文のみデータベースに問い合わせています。
record.name # first access reads value from database
record.name # second access gets value from cache
1 つのレコードに 1 つのフィールドを一度に読み取ることを避けるために、Odoo prefetches レコードとフィールドは、いくつかのヒューリスティックに従って良いパフォーマンスを得るために。 特定のレコードでフィールドを読み取らなければならない場合、ORMは実際に大きなレコードセットでそのフィールドを読み取ります。 返された値をキャッシュに保存し、後で使用することができます。 プリフェッチされたレコードセットは通常、レコードが反復によって生成されるレコードセットです。 さらに、格納された単純なフィールド (真偽値、整数、浮動小数点数、文字、テキスト、日付、日付、選択、many2one) はすべて完全に取得されます。 モデルのテーブルのカラムに対応し同じクエリで効率的に取得します
以下の例を考えてみましょう。partners は 1000 レコードのレコードセットです。 プリフェッチがなければ、ループはデータベースに 2000 個のクエリを作成します。プリフェッチでは、1 個のクエリだけが作成されます。
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
プリフェッチは*セカンダリレコード*上でも機能します: リレーショナルフィールドが読み込まれると、その値(レコード)が将来のプリフェッチのために購読されます。 これらのセカンダリレコードのいずれかにアクセスすると、同じモデルからすべてのセカンダリレコードがプリセットされます。 以下の例では、2つのクエリしか生成されません。1つはパートナー向け、1つは国向けに作成されます。
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
関連項目
search_fetch() と etch() はレコードのキャッシュを生成するために使用できます。通常、プリフェッチのメカニズムがうまく機能しない場合に使用されます。
メソッドデコレーター¶
環境¶
>>> records.env
<Environment object ...>
>>> records.env.uid
3
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...>
他のレコードセットからレコードセットを作成する場合、環境は継承されます。 環境は、他のモデルで空のレコードセットを取得し、そのモデルをクエリするために使用できます。
>>> self.env['res.partner']
res.partner()
>>> self.env['res.partner'].search([('is_company', '=', True), ('customer', '=', True)])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
いくつかの怠惰なプロパティは、環境 (コンテキスト) データにアクセスできます:
有用な環境メソッド¶
環境の変更¶
SQLの実行¶
:attr:`~odoo.api.Environment. 環境上のr`属性は、現在のデータベーストランザクションのカーソルであり、SQLを直接実行することができます。 ORMを使って表現しにくいクエリのいずれか (e. を選択します。
self.env.cr.execute("some_sql", params)
警告
生のSQLを実行すると、ORMとその結果としてOdooセキュリティルールがバイパスされます。 ユーザー入力を使用するときにクエリがサニタイズされていることを確認し、SQLクエリを使用する必要がない場合はORMユーティリティを使用することを好むようにしてください。
SQLクエリを構築するための推奨方法は、ラッパーオブジェクトを使用することです。
モデルについて知っておくべき重要なことの1つは、必ずしもすぐにデータベースの更新を実行するわけではないことです。 実際、パフォーマンス上の理由から、レコードを変更した後のフィールドの再計算を遅延させます。 また、いくつかのデータベースの更新も遅れています。 したがって、データベースをクエリする前に、クエリに関連するデータが含まれていることを確認する必要があります。 この操作は flushing と呼ばれ、期待されるデータベースの更新を実行します。
Example
# make sure that 'partner_id' is up-to-date in database
self.env['model'].flush_model(['partner_id'])
self.env.cr.execute(SQL("SELECT id FROM model WHERE partner_id IN %s", ids))
ids = [row[0] for row in self.env.cr.fetchall()]
SQLクエリごとに、クエリに必要なデータをフラッシュする必要があります。フラッシュには、それぞれ独自のAPIを持つ3つのレベルがあります。 モデルのすべての記録、または特定の記録をフラッシュすることができます。 アップデートの遅延は一般的にパフォーマンスを向上させるため、フラッシュする際には*固有*であることをお勧めします。
モデルは同じカーソルと api を使用するためです。 n環境設定では、さまざまなキャッシュを保持していますが、生SQLでデータベースを*変更*した場合や、モデルの使用が不整合になる場合があります。 ``CREATE`、UPDATE または DELETE をSQLで使用する場合、キャッシュをクリアする必要がありますが、SELECT (単純にデータベースを読み込む) ではありません。
Example
# make sure 'state' is up-to-date in database
self.env['model'].flush_model(['state'])
self.env.cr.execute("UPDATE model SET state=%s WHERE state=%s", ['new', 'old'])
# invalidate 'state' from the cache
self.env['model'].invalidate_model(['state'])
フラッシュと同じように、キャッシュ全体、モデルのすべてのレコードのキャッシュ、または特定のレコードのキャッシュを無効にすることができます。 モデルのレコードやすべてのレコードの特定のフィールドを無効にすることもできます。 キャッシュは一般的にパフォーマンスを向上させるため、無効にすると 具体的 にすることをお勧めします。
上記の方法では、キャッシュとデータベースが互いに一致しています。 しかし、もしデータベース内で計算フィールドの依存関係が変更された場合、再計算される計算フィールドをモデルに通知する必要があります。 フレームワークが知っておくべきことは、*what * レコード上で変更された *what * 項目だけです。
Example
# make sure 'state' is up-to-date in database
self.env['model'].flush_model(['state'])
# use the RETURNING clause to retrieve which rows have changed
self.env.cr.execute("UPDATE model SET state=%s WHERE state=%s RETURNING id", ['new', 'old'])
ids = [row[0] for row in self.env.cr.fetchall()]
# invalidate the cache, and notify the update to the framework
records = self.env['model'].browse(ids)
records.invalidate_recordset(['state'])
records.modified(['state'])
どのレコードが変更されたかを把握する必要があります。これを行うには、多くの方法があります。おそらく追加のSQLクエリが含まれています。 上記の例では、余分なクエリを行わずに情報を取得するために、PostgreSQL の RETURNING 節を利用します。 無効にした後、更新されたレコードの modified メソッドを呼び出し、更新されたフィールドを使用します。
一般的なORMメソッド¶
作成/更新¶
検索/読み取り¶
フィールド¶
ドメインを検索¶
ドメインは基準のリストであり、それぞれの基準は (field_name, operator, value) の triple (list または tuple のいずれか)である。
field_name(str)現在のモデルのフィールド名、またはドット表記を使用して
Many2oneを通るリレーションシップ名'street'または'partner_id.country'フィールドがdatetime(time) フィールドの場合は、'field_name.granularity'を使用して日付の一部を指定することもできます。 サポートされている粒度は'year_number','クォーター_number','iso_week_number','day_of_week','day_of_month','day_of_year','hour_number','minute_number','second_number'です。これらはすべて整数を値として使用します。
operator(str)field_nameとvalueの比較に使用される演算子です。有効な演算子は次のとおりです。=等しい値
!=等しくない
>より大きい
>=以上
<より小さい
<=以下か等しい
=?unset または equal to (
valueがNoneまたはFalseの場合は true を返します。そうでない場合は=のように動作します)=likefield_nameはvalueパターンに対して一致します。 パターンの下線の_は単一文字を表します。パーセント記号%はゼロ文字以上の文字列に一致します。likefield_nameは%value%パターンに対して一致します。=likeと似ていますが、マッチする前にvalueを '%' でラップしますnot like%value%パターンと一致しませんilike大文字と小文字を区別しない
likenot ilike大文字と小文字を区別しない
not like=ilike大文字と小文字を区別しない
=likeinは、
valueのいずれかの項目に等しく、valueは項目のリストにする必要がありますnot inは、
valueのすべての項目と等しくありませんchild_ofは、
valueレコードの子孫です。(値は 1 つのアイテムまたはアイテムのリストにすることができます)モデルのセマンティクスを考慮します (例: :attr:`~odoo.models.Model._parent_name`のリレーションシップフィールドに続く)。
parent_ofは、
valueレコードの親(昇順)です (値は 1 つの項目または項目のリストにすることができます)。モデルのセマンティクスを考慮します (例: :attr:`~odoo.models.Model._parent_name`のリレーションシップフィールドに続く)。
anyfield_name( Aname.fields.Many2one`,:class:~odoo.fields.Many2one,One2many, orMany2many) が提供されたドメイン ``value`を満たした場合にマッチします。not anyfield_name(Many2one,One2many, orMany2many) は提供されたドメイン ``value`を満たします。
value変数の型は (
operatorを介して) 指定されたフィールドと比較する必要があります。
ドメインの基準は、prefix 形式の論理演算子を使用して結合できます。
'&'論理*および*、デフォルトの操作は、互いに続く基準を結合します。Arity 2(次の2つの基準または組み合わせを使用します)。
'|'論理*OR*、アリティ2。
'!'論理的な*違う*、アリティ1。
注釈
主に基準の組み合わせを否定すること 個々の基準は、一般的に負の形態を持っています (e. をクリックします。
=->!=,<->>=) ポジティブを否定するよりもシンプルです。
Example
*7620*を含む電話番号または携帯電話番号で、*ABC*という名前のパートナーを検索するには:
[('name', '=', 'ABC'),
'|', ('phone','ilike','7620'), ('mobile', 'ilike', '7620')]
在庫切れの商品に少なくとも1行以上の請求書がある販売注文を検索するには:
[('invoice_status', '=', 'to invoice'),
('order_line', 'any', [('product_id.qty_available', '<=', 0)])]
2月に生まれたすべてのパートナーを検索するには:
[('birthday.month_number', '=', 2)]
リンクを解除¶
レコード(セット)情報¶
- odoo.models.env¶
指定されたレコードセットの環境を返します。
- タイプ
Environment
オペレーション¶
レコードセットは不変ですが、同じモデルのセットは、さまざまなセット操作で組み合わせることができ、新しいレコードセットを返します。
recordはset内に``record`` (1要素のレコードセットでなければなりません)が存在するかどうかを返します。record内にない``record`` は逆演算です。set1 <= set2とset1 < set2を返すset1がset2(resp. strict)set1 >= set2とset1 > set2returnset1がset2(resp. strict)set1 | set2は、いずれかのソースに存在するすべてのレコードを含む新しいレコードセットの 2 つのレコードセットの和を返します。set1 & set2は、両方のソースに存在するレコードのみを含む新しいレコードセットの 2 つのレコードセットの交点を返します。set1 - set2は、set1のレコードのみを含む新しいレコードセットを返します。
Recordsets are iterable so the usual Python tools are available for
transformation (map(), sorted(),
ifilter(), ...) however these return either a
list or an iterator, removing the ability to
call methods on their result, or to use set operations.
そのため、レコードセット自体を返す(可能な場合)以下の操作を行うことができます。
フィルター¶
マップ¶
注釈
V13 以降では、マルチリレーショナルフィールドアクセスがサポートされ、マップされた呼び出しのように動作します。
records.partner_id # == records.mapped('partner_id')
records.partner_id.bank_ids # == records.mapped('partner_id.bank_ids')
records.partner_id.mapped('name') # == records.mapped('partner_id.name')
並べ替え¶
グループ化¶
継承と拡張¶
Odooはモジュラー方法でモデルを拡張する3つの異なるメカニズムを提供します:
既存のモデルから新しいモデルを作成し、コピーに新しい情報を追加しますが、元のモジュールはそのままにします
他のモジュールで定義されているモデルを拡張し、以前のバージョンを置き換えます
モデルのフィールドの一部をレコードに委任する
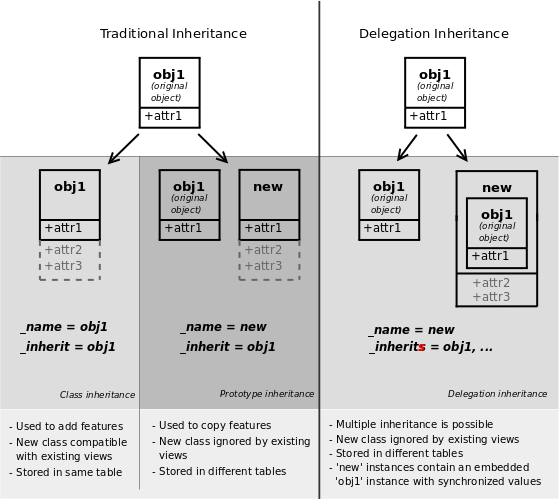
古典的な継承¶
When using the _inherit and
_name attributes together, Odoo creates a new
model using the existing one (provided via
_inherit) as a base. The new model gets all the
fields, methods and meta-information (defaults & al) from its base.
class Inheritance0(models.Model):
_name = 'inheritance.0'
_description = 'Inheritance Zero'
name = fields.Char()
def call(self):
return self.check("model 0")
def check(self, s):
return "This is {} record {}".format(s, self.name)
class Inheritance1(models.Model):
_name = 'inheritance.1'
_inherit = 'inheritance.0'
_description = 'Inheritance One'
def call(self):
return self.check("model 1")
そしてそれらを使うには
a = env['inheritance.0'].create({'name': 'A'})
b = env['inheritance.1'].create({'name': 'B'})
a.call()
b.call()
利回り:
"This is model 0 record A" "This is model 1 record B"
2番目のモデルは、最初のモデルの check メソッドと name フィールドから継承されています。 標準の Python継承 <python:tut-inheritance> ` を使用する場合と同様に ``call` メソッドをオーバーライドします。
エクステンション¶
_継承 を使用していて、 _name を省略している場合、新しいモデルは既存のモデルに置き換えられ、基本的にその場で拡張されます。 これは、(他のモジュールで作成された)既存のモデルに新しいフィールドやメソッドを追加したり、それらをカスタマイズまたは再構成したりする場合に便利です。 をクリックしてデフォルトのソート順を変更します。
class Extension0(models.Model):
_name = 'extension.0'
_description = 'Extension zero'
name = fields.Char(default="A")
class Extension1(models.Model):
_inherit = 'extension.0'
description = fields.Char(default="Extended")
record = env['extension.0'].create({})
record.read()[0]
will yield:
{'name': "A", 'description': "Extended"}
注釈
無効化されていない限り、様々な 自動フィールド も表示されます。
Delegation¶
The third inheritance mechanism provides more flexibility (it can be altered
at runtime) but less power: using the _inherits
a model delegates the lookup of any field not found on the current model
to "children" models. The delegation is performed via
Reference fields automatically set up on the parent
model.
主な違いは意味です。 デリゲーションを使用する場合、モデルは**1つ**ではなく**1つ**であり、継承する代わりにコンポジションの関係を回します::
class Screen(models.Model):
_name = 'delegation.screen'
_description = 'Screen'
size = fields.Float(string='Screen Size in inches')
class Keyboard(models.Model):
_name = 'delegation.keyboard'
_description = 'Keyboard'
layout = fields.Char(string='Layout')
class Laptop(models.Model):
_name = 'delegation.laptop'
_description = 'Laptop'
_inherits = {
'delegation.screen': 'screen_id',
'delegation.keyboard': 'keyboard_id',
}
name = fields.Char(string='Name')
maker = fields.Char(string='Maker')
# a Laptop has a screen
screen_id = fields.Many2one('delegation.screen', required=True, ondelete="cascade")
# a Laptop has a keyboard
keyboard_id = fields.Many2one('delegation.keyboard', required=True, ondelete="cascade")
record = env['delegation.laptop'].create({
'screen_id': env['delegation.screen'].create({'size': 13.0}).id,
'keyboard_id': env['delegation.keyboard'].create({'layout': 'QWERTY'}).id,
})
record.size
record.layout
will result in:
13.0
'QWERTY'
委任されたフィールドに直接書き込むことができます:
record.write({'size': 14.0})
警告
委譲継承を使用する場合、メソッドは継承されません*。フィールドのみです。
警告
_継承は多かれ少なかれ実装されています。可能な場合は避けてください。チェーン状の
_継承は本質的には実装されていません。最終的な動作について何も保証することはできません。
フィールドの増分定義¶
フィールドはモデルクラスのクラス属性として定義されます。 モデルが拡張されている場合 同じ名前と同じ型のサブクラスを持つフィールドを再定義することで、フィールド定義を拡張することもできます。 その場合、フィールドの属性は親クラスから取得され、サブクラスで与えられたものによって上書きされます。
例えば、以下の2番目のクラスは、state:: フィールドにツールチップを追加するだけです。
class First(models.Model):
_name = 'foo'
state = fields.Selection([...], required=True)
class Second(models.Model):
_inherit = 'foo'
state = fields.Selection(help="Blah blah blah")