パフォーマンス¶
Profiling¶
プロファイリングとは、プログラムの実行を分析し、集計されたデータを測定することです。 これらのデータは、各関数の経過時間、実行されたSQLクエリです。
プロファイリングだけではプログラムのパフォーマンスは向上しません。 パフォーマンスの問題を見つけるのに非常に役立つことがわかります プログラムのどの部分がそれを担当しているかを特定するのにも役立ちます
Odooは、実行中にすべての実行クエリとスタックトレースを記録することができる統合プロファイルツールを提供します。 ユーザーセッションのリクエストのセット、またはコードの特定の部分をプロファイルするために使用できます。 プロファイリングの結果は、統合された`speedscope <https://github.com/jlfwong/speedscope>`_ オープンソースアプリで検査し、Flamegraph ビューを視覚化することも、最初に JSON ファイルまたはデータベースに保存することでカスタムツールで分析することもできます。
プロファイラを有効にする¶
プロファイラは、ユーザーインターフェイスから有効にすることができます。これは最も簡単な方法ですが、Webリクエストのみをプロファイリングできます。 またはPythonコードから、テストを含む任意のコードをプロファイリングできます。
:ref:`Enable the developer mode <developer-mode> ` 。
プロファイリングセッションを開始する前に、データベース上でプロファイラをグローバルに有効にする必要があります。これは2つの方法で行うことができます:
Open the developer mode tools, then toggle the Enable profiling button. A wizard suggests a set of expiry times for the profiling. Click on ENABLE PROFILING to enable the profiler globally.

Settings --> General Settings --> Performance に移動し、希望する時刻を Enable profiling until フィールドに設定します。
After the profiler is enabled on the database, users can enable it on their session. To do so, toggle the Enable profiling button in the developer mode tools again. By default, the recommended options Record sql and Record traces are enabled. To learn more about the different options, head over to コレクション.
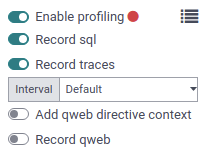
プロファイラが有効な場合、サーバーへのリクエストはすべてプロファイルされ、`ir.profile`レコードに保存されます。 このようなレコードは、プロファイラが有効になってから無効になるまで、現在のプロファイリングセッションにグループ化されます。
注釈
Odoo Online データベースはプロファイルできません。
プロファイラを手動で起動すると、特定のメソッドまたはコードの一部をプロファイルするのに便利です。 このコードはテスト、計算メソッド、ロード全体などです。
プロファイラをPythonコードから起動するには、コンテキストマネージャとして呼び出します。パラメータを通して記録したい*what*を指定できます。 self.profile() をプロファイリングするためのショートカットが利用できます。collectors パラメータの詳細については、 performance/profile/collectors を参照してください。
Example
with Profiler():
do_stuff()
Example
with Profiler(collectors=['sql', PeriodicCollector(interval=0.1)]):
do_stuff()
Example
with self.profile():
with self.assertQueryCount(__system__=1211):
do_stuff()
注釈
プロファイラは、コンテキストマネージャー(フラッシュなど)を終了したときに行われたクエリをキャッチするために、assertQueryCount の外側で呼び出されます。
プロファイラを有効にすると、テストメソッドのすべての実行がプロファイルされ、ir.profile`レコードに保存されます。 このようなレコードは単一のプロファイリングセッションにグループ化されます。これは、 :code:`@warmup と @users デコレータを使用する場合に特に便利です。
ちなみに
すべての呼び出しがスタックトレース内でまとめられているため、数回呼び出されるメソッドのプロファイリング結果を分析するのは複雑なことがあります。 結果を複数のフレームに分解するために、コンテキストマネージャーとして 実行コンテキスト を追加します。
Example
for index in range(max_index):
with ExecutionContext(current_index=index): # Identify each call in speedscope results.
do_stuff()
結果の分析¶
To browse the profiling results, make sure that the profiler is enabled globally on the
database, then open the developer mode tools and click on the button in the top-right corner of the profiling
section. A list view of the ir.profile records grouped by profiling session opens.
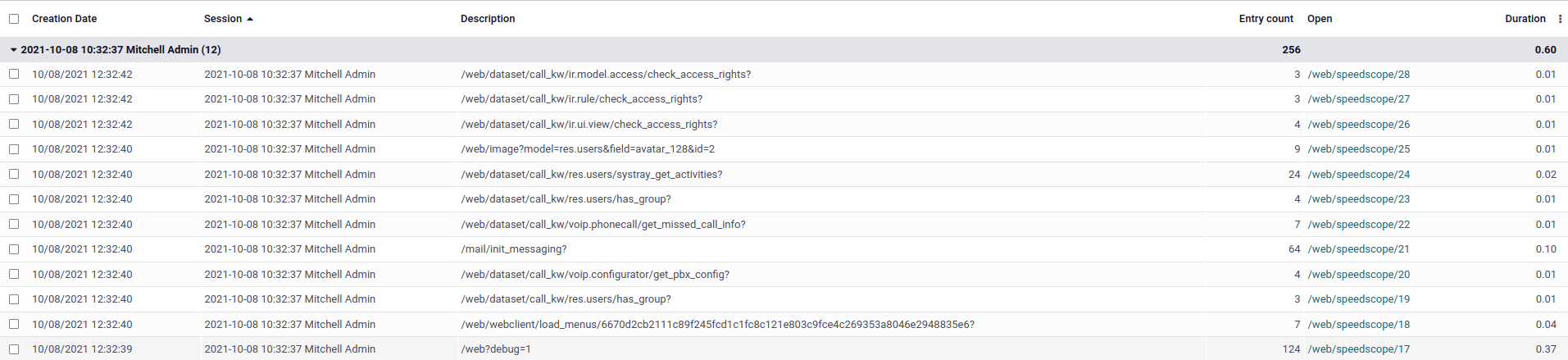
各レコードにはクリック可能なリンクがあり、スピードスコープの結果を新しいタブで開きます。
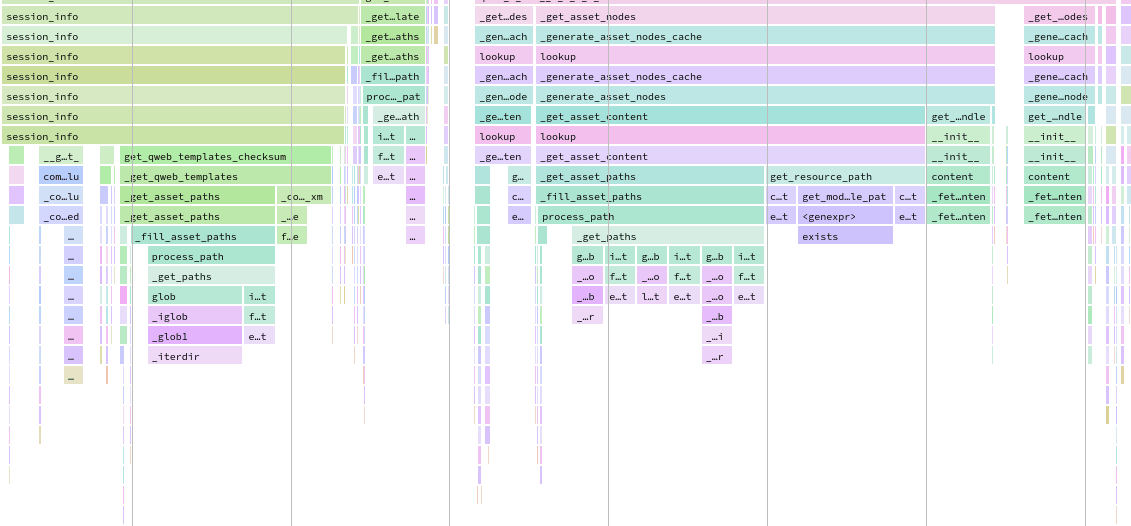
Speedscopeはこのドキュメントの範囲外ですが、試すツールがたくさんあります: search。 似たようなフレームのハイライト、ズーム、タイムライン、左の重い、サンドイッチビュー...
アクティブ化されたプロファイリングオプションに応じて、Odoo はトップメニューからアクセスできるさまざまなビューモードを生成します。
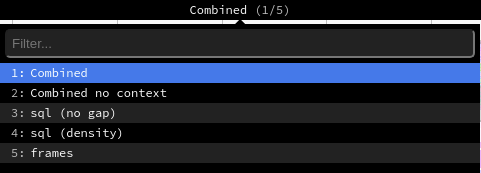
Combined ビューには、すべての SQL クエリとトレースがまとめられて表示されます。
Contextなしの結合 ビューは同じ結果を表示しますが、保存された実行コンテキスト <performance/profiling/enable> を無視します。
:guilabel:`sql (no gap)`ビューは、Pythonロジックなしで次々に実行されたかのようにすべてのSQLクエリを表示します。 これはSQLのみを最適化するのに役立ちます。
sql (density) ビューには、すべての SQL クエリのみが表示されます。 これは、eiter SQLやPythonのコードが問題であるかどうかを特定するのに便利です。 多くの小さなクエリがバッチ処理されるゾーンを特定することができます
frames ビューには、 :ref:`周期コレクタ <performance/profiling/collectors/periodic> `のみの結果が表示されます。
重要
プロファイラはできるだけ軽く設計されていますが、 特に Sync collector を使用すると、パフォーマンスに影響を与える可能性があります。 スピードスコープの結果を分析する際には、それを覚えておいてください。
コレクション¶
プロファイラーは いつ プロファイリングについてですが、コレクターは*何*を処理します。
各コレクターは、独自の形式と方法でプロファイリングデータを収集することに特化しています。 :ref:`developer mode tools <developer-mode/tools>`の専用のトグルボタンを介して、ユーザーインターフェースから個別に有効にすることができます。 またはPythonのコードからキーやクラスを通過します。
現在、4つのコレクターがOdooで利用できます:
名前(name) |
トグルボタン |
Python key |
Python クラス |
|---|---|---|---|
Record sql |
|
|
|
トレースを記録 |
|
|
|
Record qweb |
|
|
|
いいえ |
|
|
デフォルトでは、プロファイラはSQLとPeriodic Collectorを有効にします。どちらもユーザーインターフェイスまたはPythonコードで有効になっている場合です。
SQL コレクタ¶
SQLコレクタは、現在のスレッド(すべてのカーソルの場合)でデータベースに作成されたすべてのSQLクエリとスタックトレースを保存します。 各クエリの解析スレッドにコレクターのオーバーヘッドが追加されます。 多くの小さなクエリで使うと実行時間や他のプロファイラーに影響を与えることになります
クエリ数をデバッグしたり、スピードスコープビューで Periodic collector に情報を追加したりするのに特に便利です。
周期的なコレクション¶
このコレクタは別々のスレッドで実行され、分析されたスレッドのスタックトレースを各間隔で保存します。 インターバルは、ユーザーインターフェイスの Interval オプションにより定義することができます。 または Python コードの interval パラメータ。
警告
インターバルが非常に低い値に設定されている場合、長いリクエストをプロファイリングするとメモリの問題が発生します。 インターバルが非常に高い値に設定されている場合、短関数の実行に関する情報は失われます。
パフォーマンスを分析する最良の方法の1つで、実行時間に非常に低い影響を与える必要があります。
QWeb コレクタ¶
このコレクターは、すべてのディレクティブの Python 実行時間とクエリを保存します。 SQL collector <performance/profiling/collectors/sql>`については、多くの小さなディレクティブを実行する際にオーバーヘッドが重要になります。 結果は収集されたデータの点で他のコレクターとは異なり、カスタム ウィジェットを使用して `ir.profile フォーム ビューから分析できます。
これは主にビューを最適化するのに役立ちます。
コレクターを同期¶
このコレクタは、すべての関数の呼び出しとリターンのスタックを同じスレッドで保存し、パフォーマンスに大きな影響を与えます。
複雑なフローをデバッグして理解し、コード内で実行するのに役立ちます。 ただし、オーバーヘッドが高いので、性能分析には推奨されません。
パフォーマンスの落とし穴¶
乱数に注意してください。複数の実行は異なる結果につながる可能性があります。例えば、実行中にガベージコレクタがトリガーされます。
着信のブロックには注意してください。 GILをリリースする前に、外部の`c_call`に時間がかかる場合があります。 したがって、 :ref:`定期コレクター <performance/profiling/collectors/periodic>`で予期しない長いフレームが発生します。 これはプロファイラによって検出され、警告を与える必要があります。必要に応じて、そのような呼び出しの前に手動でプロファイラをトリガーすることは可能です。
キャッシュに注意してください。
view/assets/...キャッシュにある前のプロファイルは、異なる結果をもたらす可能性があります。プロファイラのオーバーヘッドに注意してください。 :ref:`SQL collector <performance/profiling/collectors/sql>`のオーバーヘッドは、多くの小さなクエリが実行されるときに重要です。 プロファイルは問題を特定するのに実用的ですが、コード変更の実際の影響を測定するためにプロファイラを無効にしたい場合があります。
プロファイリングの結果はメモリを必要とする場合があります。場合によっては(例えば)。 インストールまたは長いリクエストをプロファイリングする)、メモリ制限に達する可能性があります。 特に、HTTP 500エラーにつながるスピードスコープの結果をレンダリングする場合。 この場合、`--limit-memory-hard $((8*1024**3))`より高いメモリ制限でサーバを起動する必要があります。
グッドプラクティスformat@@0¶
一括操作¶
レコードセットを扱う場合は、バッチ処理にはほぼ常に優れています。
Example
レコードセットをループオーバーしながらSQLクエリを実行するメソッドを呼び出さないでください。これは、セットの各レコードに対して実行されるからです。
def _compute_count(self):
for record in self:
domain = [('related_id', '=', record.id)]
record.count = other_model.search_count(domain)
代わりに、search_count を _read_group に置き換えて、レコード全体の SQL クエリを実行します。
def _compute_count(self):
domain = [('related_id', 'in', self.ids)]
counts_data = other_model._read_group(domain, ['related_id'], ['__count'])
mapped_data = dict(counts_data)
for record in self:
record.count = mapped_data.get(record, 0)
注釈
この例は、すべての場合に最適でも正しくもありません。search_count の代用に過ぎません。 もう一つの解決方法は、One2many フィールドを先読みして数えることです。
Example
次々にレコードを作成しないでください。
for name in ['foo', 'bar']:
model.create({'name': name})
代わりに、生成値を蓄積し、バッチで create メソッドを呼び出します。 そうすることはほとんど影響を与えず、フレームワークがフィールドの計算を最適化するのに役立ちます。
create_values = []
for name in ['foo', 'bar']:
create_values.append({'name': name})
records = model.create(create_values)
Example
ループ内で単一のレコードを参照しているときに、レコードセットのフィールドを先読みすることに失敗しました。
for record_id in record_ids:
model.browse(record_id)
record.foo # One query is executed per record.
代わりに、最初にレコードセット全体を参照します。
records = model.browse(record_ids)
for record in records:
record.foo # One query is executed for the entire recordset.
レコードが prefetch_ids の各レコード ID を含む項目を読み取ることで、レコードがバッチで先読みされていることを確認できます。 全てのレコードを一緒に漕ぐのは非現実的です
必要に応じて、 with_prefetch メソッドを使用してバッチ先読みを無効にすることができます。
for values in values_list:
message = self.browse(values['id']).with_prefetch(self.ids)
アルゴリズムの複雑さを減らす¶
アルゴリズムの複雑さとは、入力のサイズ`n`に関してアルゴリズムが完了するまでにかかる時間の尺度です。 複雑性が高い場合、入力が大きくなるにつれて実行時間が短くなることがあります。 場合によっては、入力のデータを正しく準備することで、アルゴリズムの複雑さを軽減することができます。
Example
特定の問題については、O(n2)の複雑さを示す2つのネストされたループで作成された純粋なアルゴリズムを考えてみましょう。
for record in self:
for result in results:
if results['id'] == record.id:
record.foo = results['foo']
break
すべての結果が異なるIDを持つと仮定すると、複雑さを軽減するためにデータを準備することができます。
mapped_result = {result['id']: result['foo'] for result in results}
for record in self:
record.foo = mapped_result.get(record.id)
Example
入力を保持するために悪いデータ構造を選択すると、二次的な複雑性が生じる可能性があります。
invalid_ids = self.search(domain).ids
for record in self:
if record.id in invalid_ids:
...
`invalid_ids`がリストのようなデータ構造の場合、アルゴリズムの複雑さは2乗になります。
代わりに、invalid_ids をセットにキャストするような設定操作を使う方を選びます。
invalid_ids = set(invalid_ids)
for record in self:
if record.id in invalid_ids:
...
入力に応じて、レコードセット操作も使用できます。
invalid_ids = self.search(domain)
for record in self - invalid_ids:
...
インデックスを使用¶
データベースインデックスは、ユーザーインターフェイス内またはユーザーインターフェイス内の検索から、検索操作を固定するのに役立ちます。
name = fields.Char(string="Name", index=True)
警告
インデックスは、INSERT、UPDATE、および `DELETE`のいずれかを実行するときに、すべてのフィールドをインデックスすることはスペースとパフォーマンスに影響を与えるので、注意してください。